
Das bewährte Monitoring & Schutzsystem für den stationären Langzeiteinsatz.
Die Zentrale für dynamische Daten
Speicherung und Verteilung von Daten mit DEr software IFTA DataHub
In der IFTA DataHub Software laufen alle Daten auf einem Windows basiertem PC zusammen, um sie zu archivieren, zu speichern und online im Netzwerk für die Visualisierung zu verteilen. Als Datenquelle sind hier der IFTA SignalMiner mit den dynamischen Daten zu nennen, aber auch weitere Daten per OPC, DataSocket oder anderen proprietären Schnittstellen, welche den Betriebspunkt der Maschine oder Umweltbedingungen festhalten. Das Zusammenführen dieser Daten erlaubt es, die dynamischen Daten im Kontext zu betrachten. Darüber hinaus werden kompakte Übersichtsdateien erzeugt, indem Daten zeitlich und logisch zusammengefasst werden. So ist es möglich eine tägliche Übersicht über das Maschinenverhalten zu ermöglichen, die nur wenige MB an Daten benötigt und auch leicht remote abrufbar ist. Die Speicherung, Triggerung, Filterung und Zusammenfassung kann frei parametriert werden.
Langzeitdatenaufzeichnung
Läuft der IFTA DataHub auf unseren Datenserver-Lösungen, wie dem IFTA SlotPC und dem IFTA PanelPC, ermöglicht das eine intelligente Langzeitdatenerfassung über Monate und Jahre hinweg ohne zusätzliche externe Geräte verwenden zu müssen.
Langzeitanalyse dynamischer Mess- und Betriebsdaten
Die Nadel im Heuhaufen finden
Die DataHub Software sammelt Daten verschiedenster Quellen und ermöglicht damit deren kombinierte Analyse. So können unter anderem dynamische Messdaten von mehr als 100 GB/Tag aus IFTA Messsystemen zusammen mit Betriebsdaten 24/7 gespeichert und analysiert werden. Die Suche nach relevanten Ereignissen in diesen großen Datenmengen entspricht der buchstäblichen Suche nach der „Nadel im Heuhaufen“.
Bei dieser Suche unterstützt der DataHub den Anwender durch die Erstellung kleiner, leicht handhabbarer Übersichtsdateien, die einen schnellen Überblick über alle Daten und damit das Auffinden von Anomalien ermöglichen. Zusätzlich erlaubt die bereitgestellte Online-Anbindung die Echtzeitbegutachtung aller Datenströme und das Datenstreaming in die Cloud.

Datenaggregierung zur effizienten Analyse großer Datensätze
Dynamische Schwingungsmessungen generieren große Mengen an Daten
Die digitale Aufzeichnung dynamischer Schwingungsdaten erzeugt sehr schnell große Mengen an Daten. Die Erfassung von Schwingungen bis 5 kHz erfordert beispielhaft eine Datenrate von mindestens 10 000 Samples pro Sekunde (S/s). Nimmt man an, jedes einzelne Sample erfordere 4 Byte an Speicher, so führt das zu einer Datenrate von 40 kByte/s, bzw. umgerechnet 144 MByte in der Stunde oder knapp 3,5 GB am Tag. Da im Allgemeinen mehr als ein einzelner Sensor eingesetzt wird, generiert die Überwachung einer kompletten Maschine ein Vielfaches davon.
Wie funktioniert die Datenaggregierung?
Diese Datenflut bringt eine Vielzahl an Herausforderungen mit sich. Viele davon lassen sich mit der Aggregierung von Daten begegnen. Hierbei wird in Echtzeit aus Rohdaten ein „Daten-Kondensat“ mit erheblich reduziertem Speicherbedarf erzeugt, welches dennoch wesentliche Informationen beibehält. Dieses Kondensat ermöglicht schnelle Einblicke in große Datensätze und dient als Wegweiser und Indikator bei der Analyse.
Der IFTA DataHub unterstützt eine Aggregierung über die Zeit. Diese ist in Abbildung 1 illustriert. Ein hochaufgelöstes Signal wird hier über aufeinander folgende Zeitfenster jeweils zu drei Datenpunkten aggregiert: Der erste Punkt entspricht dem minimalen Wert des Signals innerhalb des Zeitfensters, der zweite dem maximalen und der dritte dem durchschnittlichen Wert. Auf diese Weise werden drei neue Signale erzeugt, welche das Ausgangssignal charakterisieren und deren zeitliche Auflösung – und damit Speicherbedarf - von der gewählten Fensterbreite abhängt.
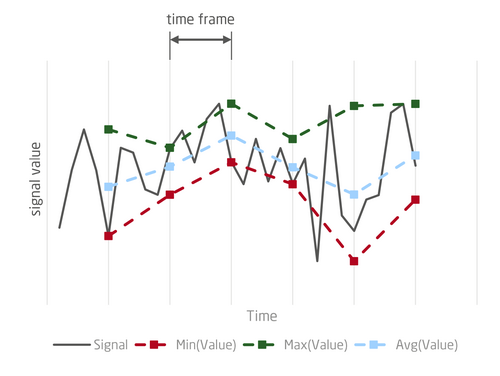
Vorteile der zeitlichen DatenAggregierung
Die zeitliche Aggregierung von Daten erlaubt es, große Zeitbereiche effizient zu analysieren. Abbildung 2 veranschaulicht diesen Vorteil. In der linken Bildhälfte sind Spektrogramme von 100 MByte an Sensordaten für zwei Aggregierungsstufen samt Rohdaten dargestellt. Während ohne Aggregierung lediglich ein sehr kurzer Zeitabschnitt abgedeckt wird (unten), lässt sich in der höchsten Aggregierungsstufe (60 s) ein sehr weiter Bereich überblicken. Wird hier eine Auffälligkeit entdeckt, kann durch Laden der nächstfeineren Aggregierungsstufe (5 s oder Rohdaten) sukzessive in die Daten hineingezoomt werden. In der rechten Bildhälfte ist dies analog für den Zeitbereich illustriert. Die zu verarbeitenden Daten werden auf diese Weise minimiert, was speicher- und recheneffizient ist und damit für große Datensätze effektives Arbeiten überhaupt erst ermöglicht.
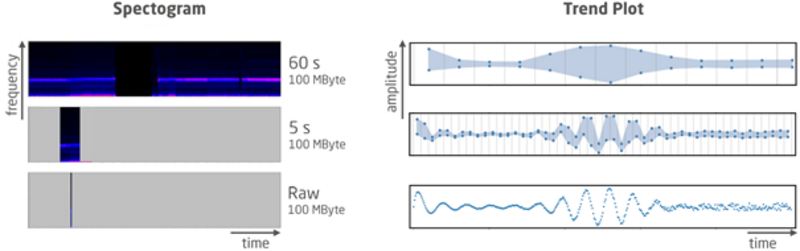
Nutzen auf einen Blick
- Schnelle Visualisierung und Analyse großer Zeitbereiche
- Zoom in Rohdaten zielgenau möglich
- Aggregierte Daten stehen sofort zur Verfügung, da die Datenaggregierung kontinuierlich während der Datenaufzeichnung erfolgt
Die Funktionen der IFTA Software DataHub
Grundaufbau
Der Grundaufbau der IFTA DataHub Software
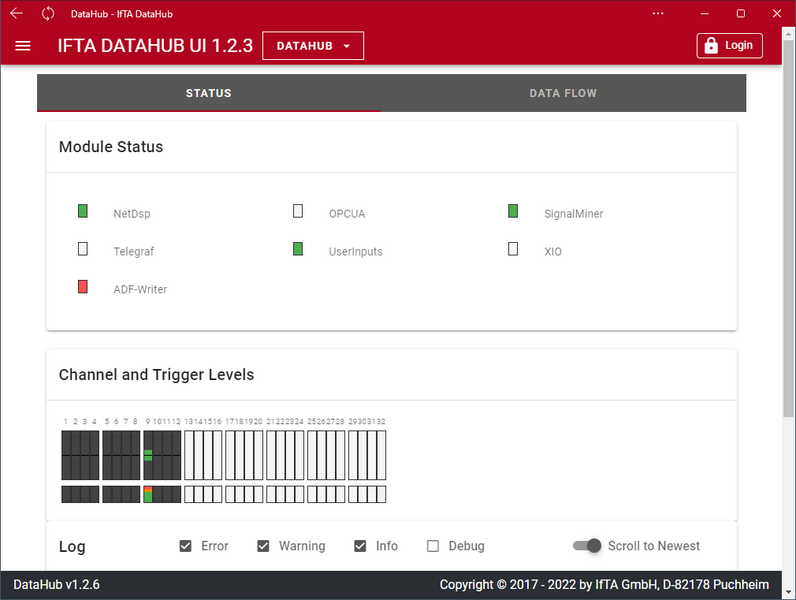
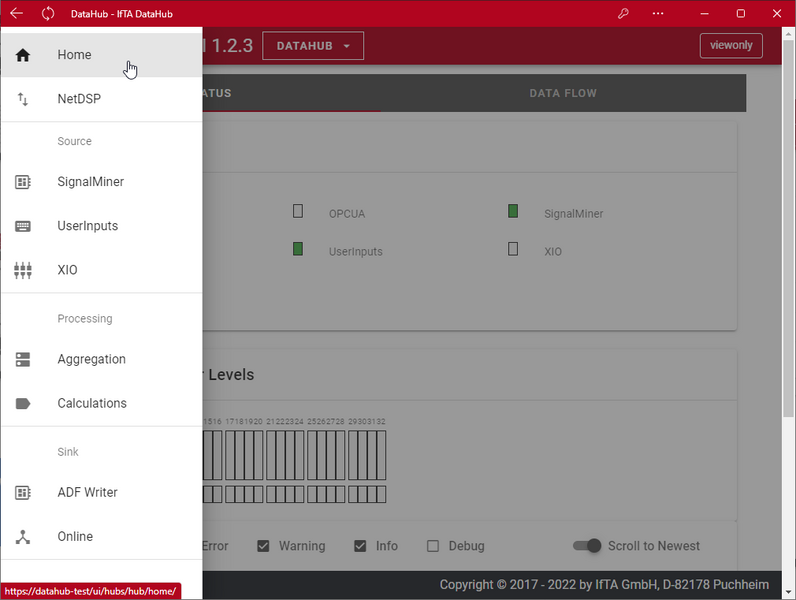
Die IFTA DataHub Software besteht aus zwei Komponenten: einem Dienst, welcher die eigentliche Arbeit im Hintergrund erledigt und einem zweiten Dienst, der eine webbasierte Schnittstelle für Anwender bietet. Durch diese Entkopplung kann höchste Zuverlässigkeit und Robustheit gewährleistet werden.
- Der Hintergrunddienst sammelt die Daten aller Datenquellen und führt diese zusammen, filtert, aggregiert und verteilt sie in Dateien für die live Visualisierung und Analyse in TrendViewer
- Die webbasierte Schnittstelle erlaubt Anwendern die Konfiguration, Statusabfrage und Interaktion per Browser - auf dem System, aber auch remote vom eigenen Laptop
- Über eine Benutzerverwaltung kann festgelegt werden, wer welche Aktionen durchführen kann
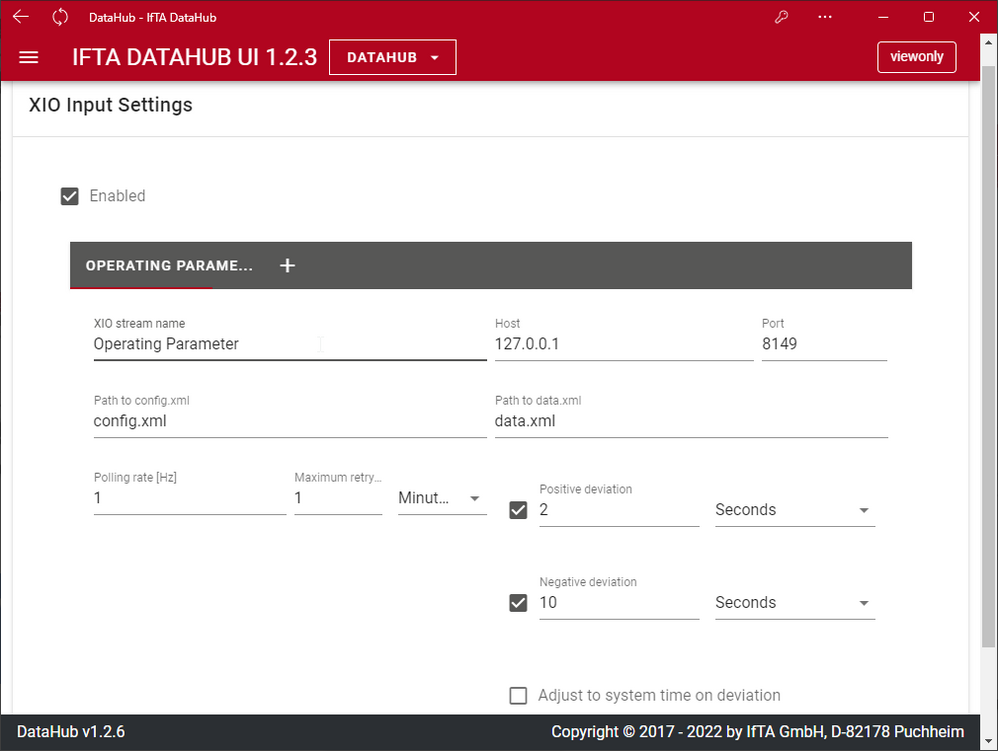
Sammeln und Zusammenführen von Messdaten - DataSocket, OPC DA, OPC UA
Sammeln und Zusammenführen von Messdaten
In den Einstellungen der Datenquellen wird konfiguriert, von woher der DataHub seine Daten bezieht. Die IFTA SignalMiner Firmware des IFTA DSP ist die Hauptdatenquelle für Messdaten - hier werden alle dynamischen Daten erfasst.
Zusätzlich zu den dynamischen Daten benötigt man in der Regel noch weitere Messwerte (Betriebsdaten, Umgebungsdaten, etc.), die über folgende Schnittstellen erfasst werden können:
- DataSocket
- OPC DA
- OPC UA
- Profibus mittels SignalMiner
- Profinet mittels SignalMiner
Auf Kundenwunsch werden auch proprietäre Schnittstellen angebunden.
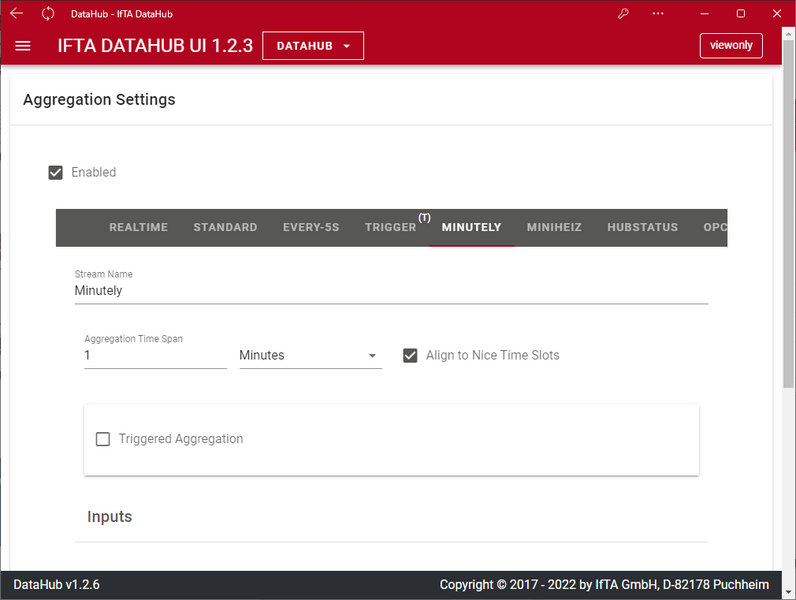
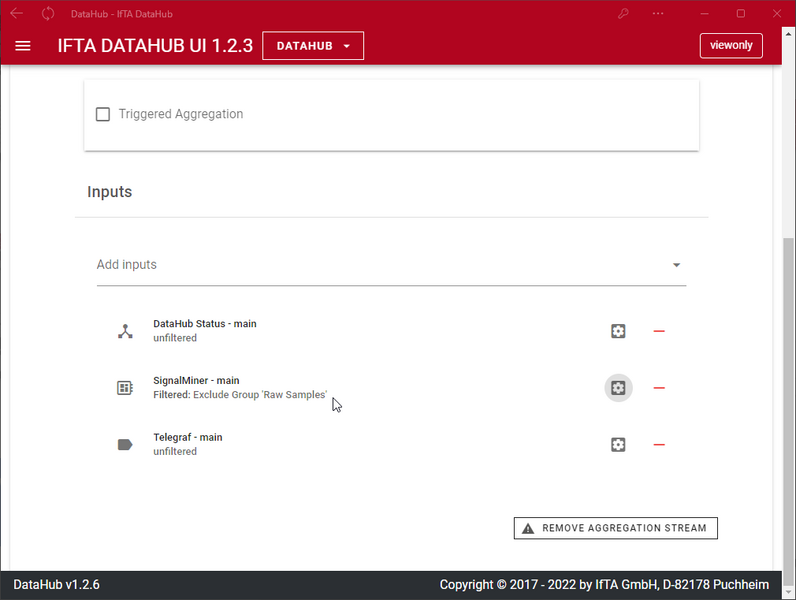
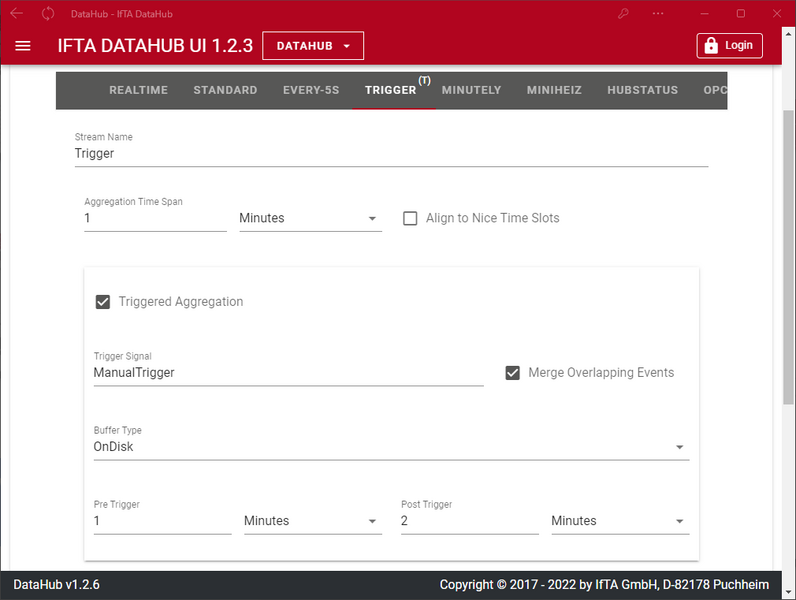
Messdaten zeitlich aggregieren, filtern und triggern
Messdaten zeitlich zusammenfassen, filtern und triggern
In den "Aggregation Settings" werden die konfigurierten Datenquellen zu neuen Datenströmen zusammengefasst.
Einstellbare Funktionen:
- Auswahl der zusammenzufassenden Quelldatenströme
- Filterung der Quelldatenströme - auf die wesentlichen beschränken Signale und damit die Datenmenge zu reduzieren
- Zeitliche Zusammenfassung der Daten, um die Datenrate und damit die Datenmenge zu reduzieren
- Getriggerte Erfassung von Daten mit einer Pre- und Post-Trigger Zeitspanne
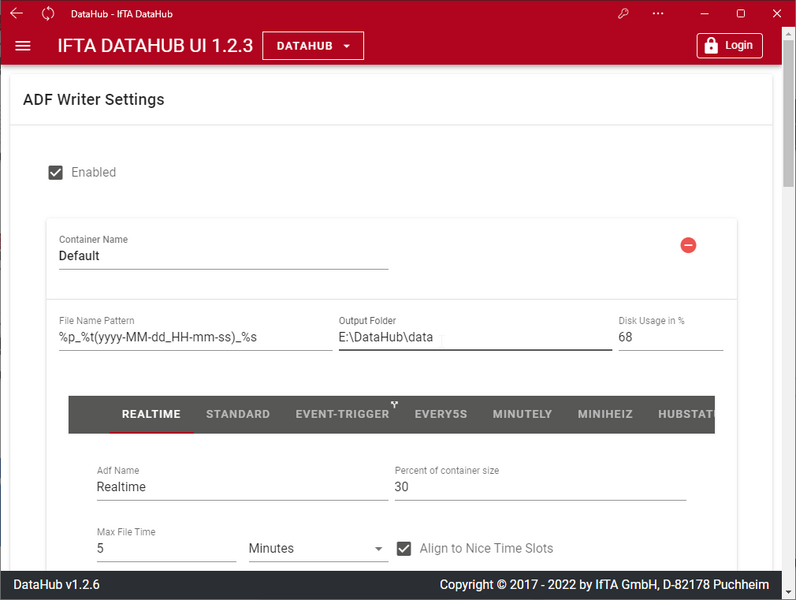
Speicherung von Messdaten für die Offline Analyse
Speicherung von Messdaten für die Offline Analyse
In den "ADF Writer Setting" wird die Speicherung der Messwerte in Dateien konfiguriert, damit diese zur späteren Offline Analyse zur Verfügung stehen, z.B. in der IFTA TrendViewer Analysesoftware. Um ein Überlaufen des Speichermediums zu verhindern, werden beim Erreichen des konfigurierten Speicherkontingents die ältesten Dateien gelöscht, um Platz für die neuen aktuellen Daten zu schaffen.
Einstellbare Funktionen:
- Festlegung des Speicherortes und des zu nutzenden Ringpufferspeicherplatzes
- Festlegung des Dateinamensmusters
- Speicherung der Datenströme nach Zeitscheiben
- Festlegung der zu speichernden Datenströme
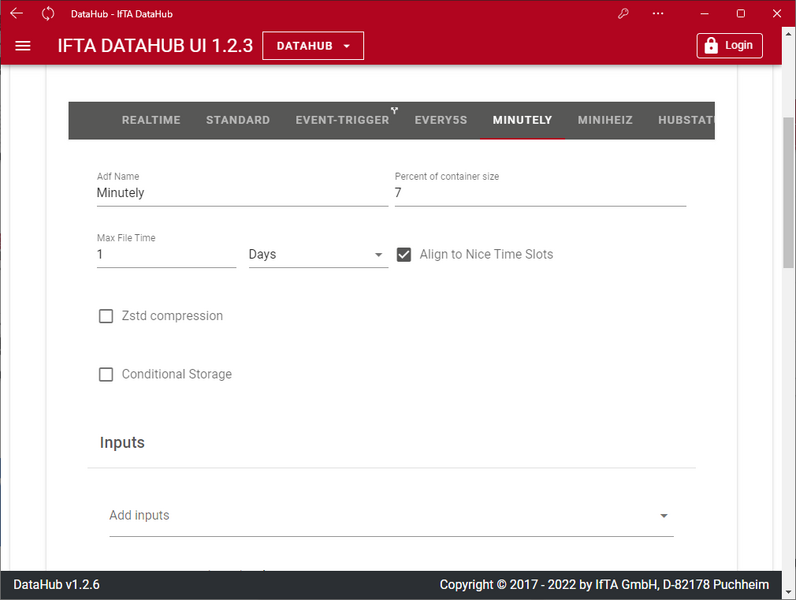
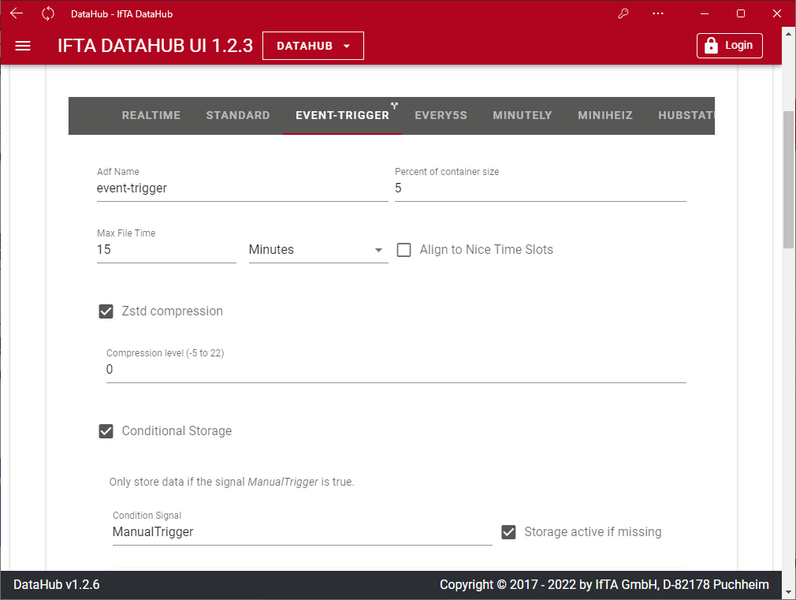
Messdaten zur Online Visualisierung bereitstellen
Messdaten zur Online Visualisierung bereitstellen
In den "Setting for the Online Server" wird das Streaming der Messdaten zu online Clients wie TrendViewer konfiguriert.
Zur kontinuierlichen Überwachung durch Anwender oder bei der Durchführung von spezifischen Messungen kann der Anwender die Messdaten hiermit live visualisieren und analysieren, z.B. mittels TrendViewer.
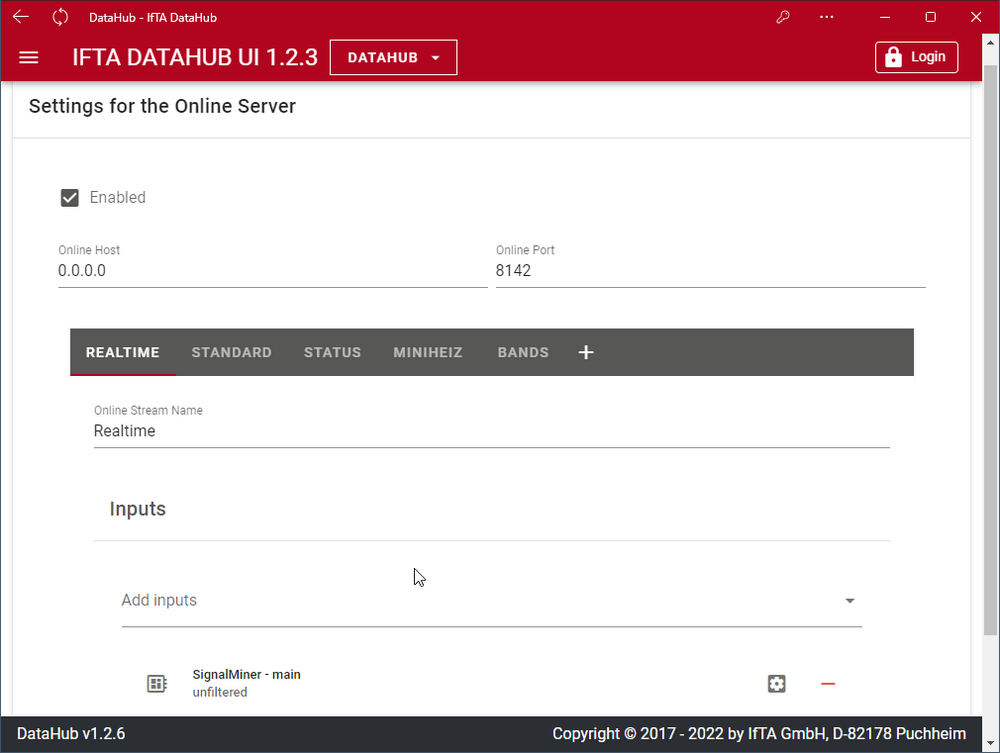
Signale durch Berechnungen definieren
Signale durch Berechnungen definieren
In den "Calculations Settings" können neben den Signalen aus den Datenquellen zusätzliche Signale per Berechnungsfunktionen erstellt werden.
Die Hauptanwendungen hierfür sind:
- Benutzerdefinierte Triggerbedingungen
- Benutzerdefinierte Speicherbedingungen
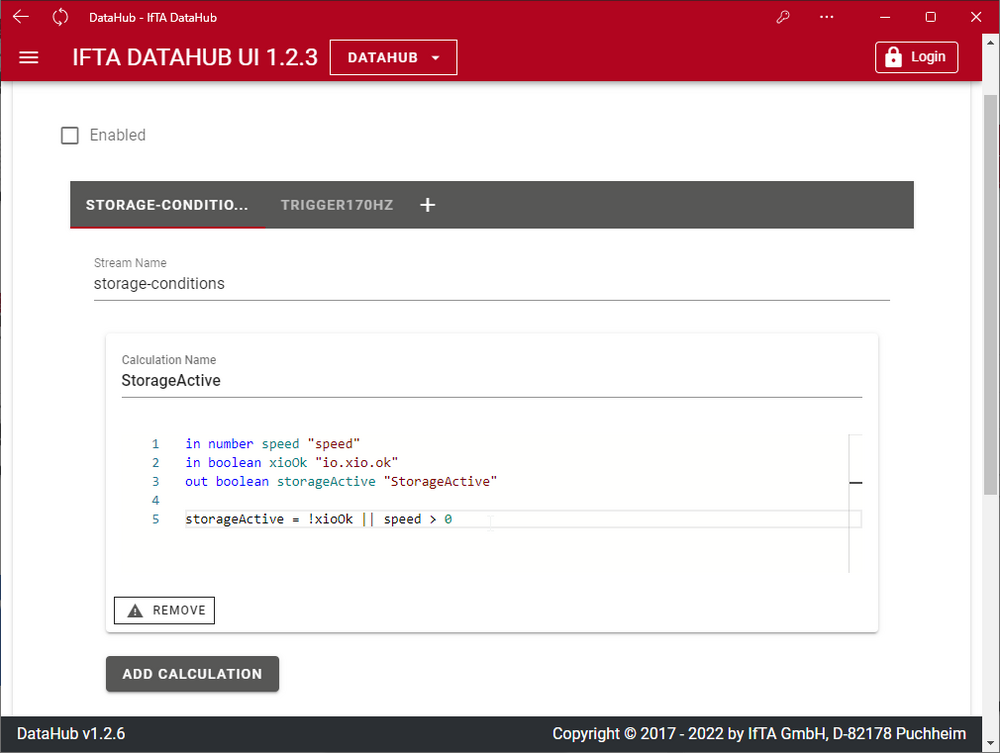
Benutzereingaben als Signal bereitstellen
Benutzereingaben als Signal bereitstellen
In den "User Input Setting" können weitere Signale als Datenquelle definiert werden die eine direkte Eingabe des Anwenders sind. Nach der Definition eines Signals kann der Anwender hier direkt Werte eingeben die zusammen mit den Messdaten gespeichert werden oder die Steuerung anderer Aktionen wie Speicherung und Triggerung übernehmen.
Die Hauptanwendungen hierfür sind:
- Manuelles Steuern der Speicherung
- Manuelles Auslösen eines Triggers
- Manuelles Erfassen anderer Informationen die nicht per Sensor oder anderer Datenquelle zur Verfügung stehen, z.B. Messpunktnummer, Umgebungsbedingungen, Zustände

1. Platz für den IFTA DataHub
Verleihung des messtec + sensor masters award 2020
Die IFTA DataHub Software wurde am 22.09.2020 mit dem 1. Platz des messtec + sensor masters award 2020 ausgezeichnet.
Dr. Jakob Hermann, Geschäftsführer der IFTA, freut sich über die Auszeichnung besonders: „Die DataHub-Software ist das Herzstück unserer Schwingungsmesssysteme. Sie sammelt dynamische Messdaten und Betriebsdaten aus unterschiedlichster Quellen und sorgt für eine smarte 24/7 Langzeit-Speicherung für spätere Analysen. 2016 wurde unsere Analyse- und Visualisierungssoftware TrendViewer ebenfalls mit dem ersten Platz ausgezeichnet. Zusammen bilden sie ein starkes und von den Lesern der MD-Automation „prämiertes“ Softwarepaket für die effiziente Ursachenanalyse von Schwingungen an Maschinen und Anlagen.“
Der nächste Schritt: Die Datenanalyse mit IFTA TrendViewer
Wenn nun die Daten über die DataHub Software gesammelt und aggregiert wurden, folgt die Analyse und Auswertung der Daten mit unserer IFTA TrendViewer Software. Hierdurch können z. B. Fehler gefunden, Daten verglichen und Entscheidungen zur Optimierung getroffen werden.
Je besser Sie Ihre Maschinen kennen, desto mehr Optimierungen sind möglich.
Produkte mit integrierter DataHub Software

DynaMaster
Diagnosetool für high-speed Analyse & intelligente Visualisierung.
